
One interesting talk at KVM Forum last week was Stefan Hajnoczi‘s talk about QEMU security (sorry, it’s not online — it should eventually be available alongside all the other talks on this youtube channel).
One thing Stefan mentioned was whether QEMU might be split into multiple processes. This has advantages for security:
- Crashing or corrupting a single process doesn’t automatically expose the whole hypervisor.
- You can separately label each process using SELinux and independently control those policies, providing finer-grained security.
For block drivers you can do this today, and in fact we do this already when we run qemu from virt-v2v. Consider the case where we are using a remote HTTPS disk image:
$ qemu -drive https://remote/disk.img
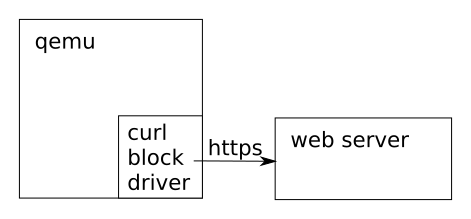
The curl driver linked to and running inside QEMU needs to make a remote TCP/IP connection, has to encode and decode TLS, is linked to libcurl and so on, and all those things also apply to the QEMU process. If the curl block driver has problems for any reason, these also affect QEMU. SELinux labels and transitions needed to access the socket are labels and transitions needed by the QEMU process. An exploit in the driver is a QEMU exploit.
With nbdkit we can split this out:
$ nbdkit -U - curl url=https://remote/disk.img \ --run 'qemu -drive $nbd'

From a security point of view this has immediate advantages: If the curl driver crashes or is exploited, only nbdkit is affected. QEMU only needs access to a private Unix domain socket, and conversely nbdkit doesn’t need access to anything else that QEMU uses. You can add resource limits, separate SELinux policy, seccomp, namespaces and anything else you can think of to nbdkit to contain it tightly.
It’s worth pointing out the obvious disadvantages too: It’s likely that there will be a performance impact — although don’t discount how efficient NBD is and how this architecture also lets you scale more effectively over NUMA nodes. And this puts all our eggs into the qemu NBD client which must be very robust.
I should say also that this is more laborious to set up, and it would only really work if some other component (libvirt ideally) handled the creation of the separate nbdkit process. In the example above I used captive nbdkit, but that only works if you have a single drive, and one of the other mechanisms would be more scalable.

